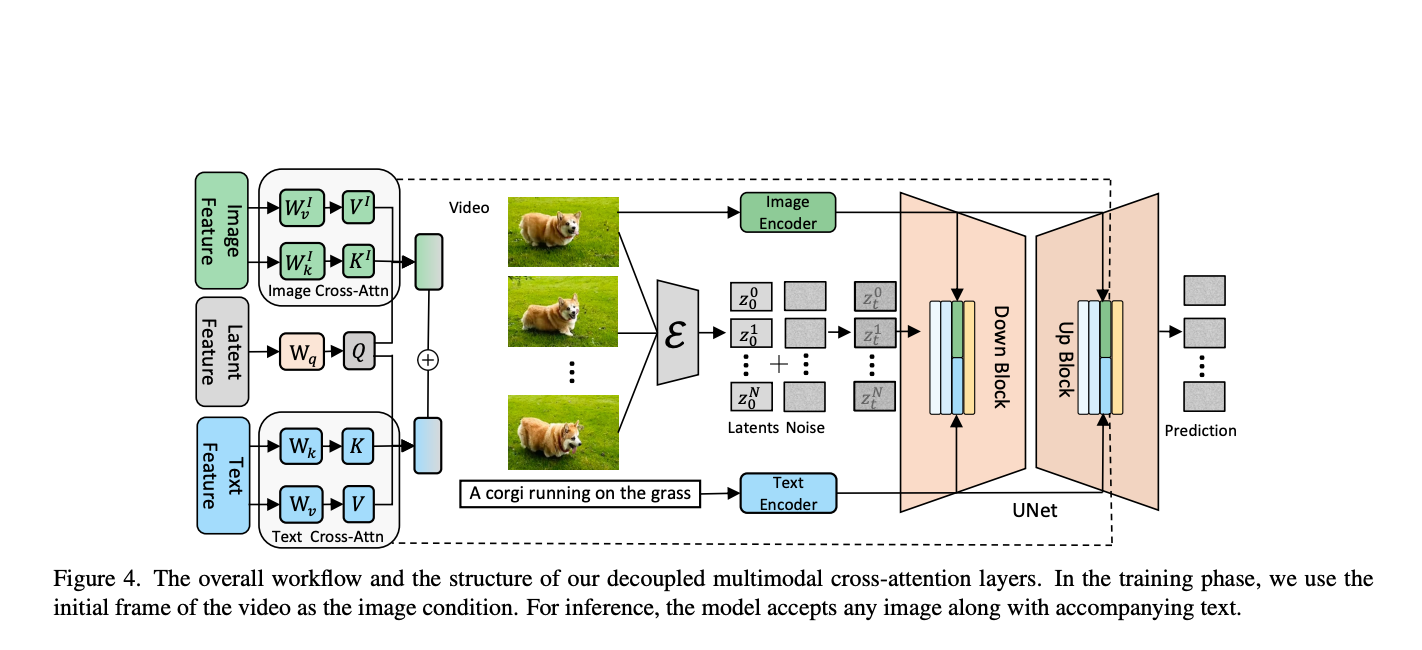
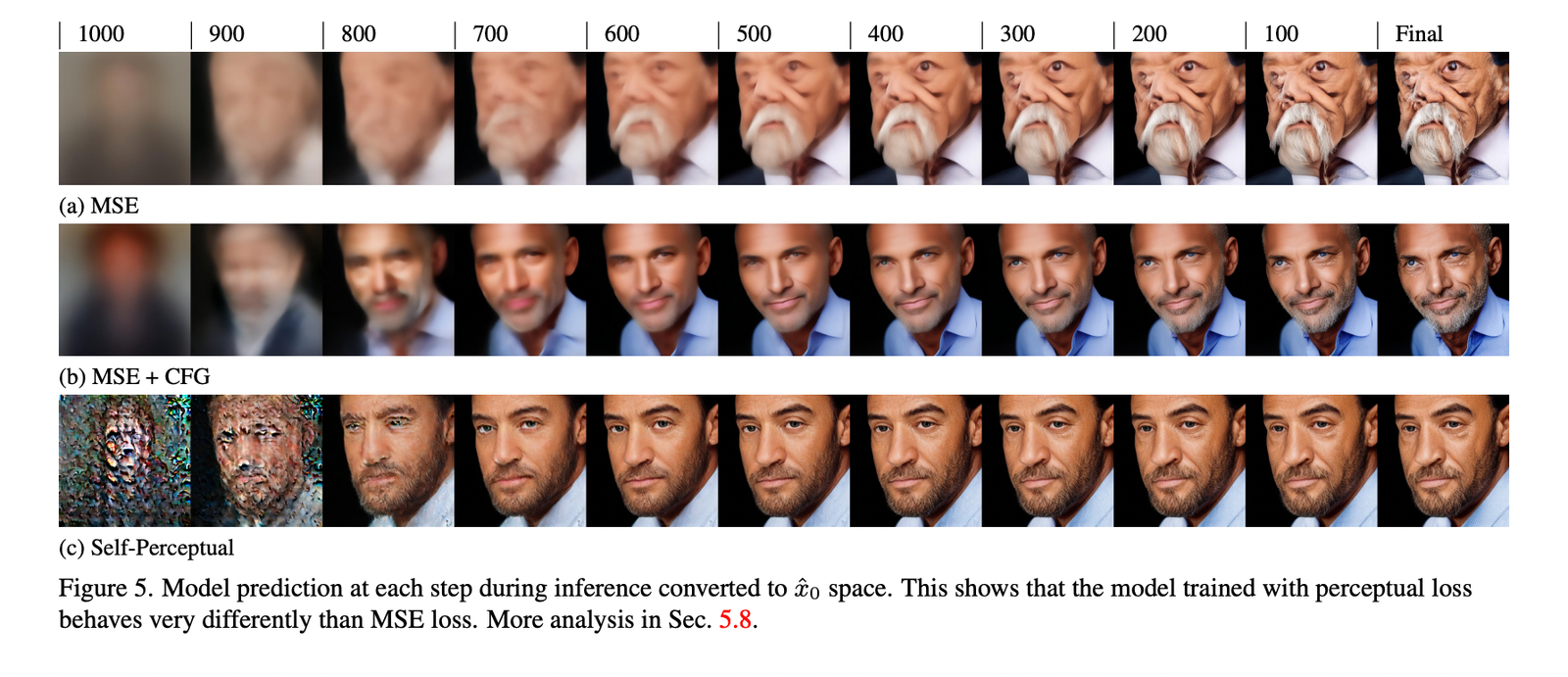
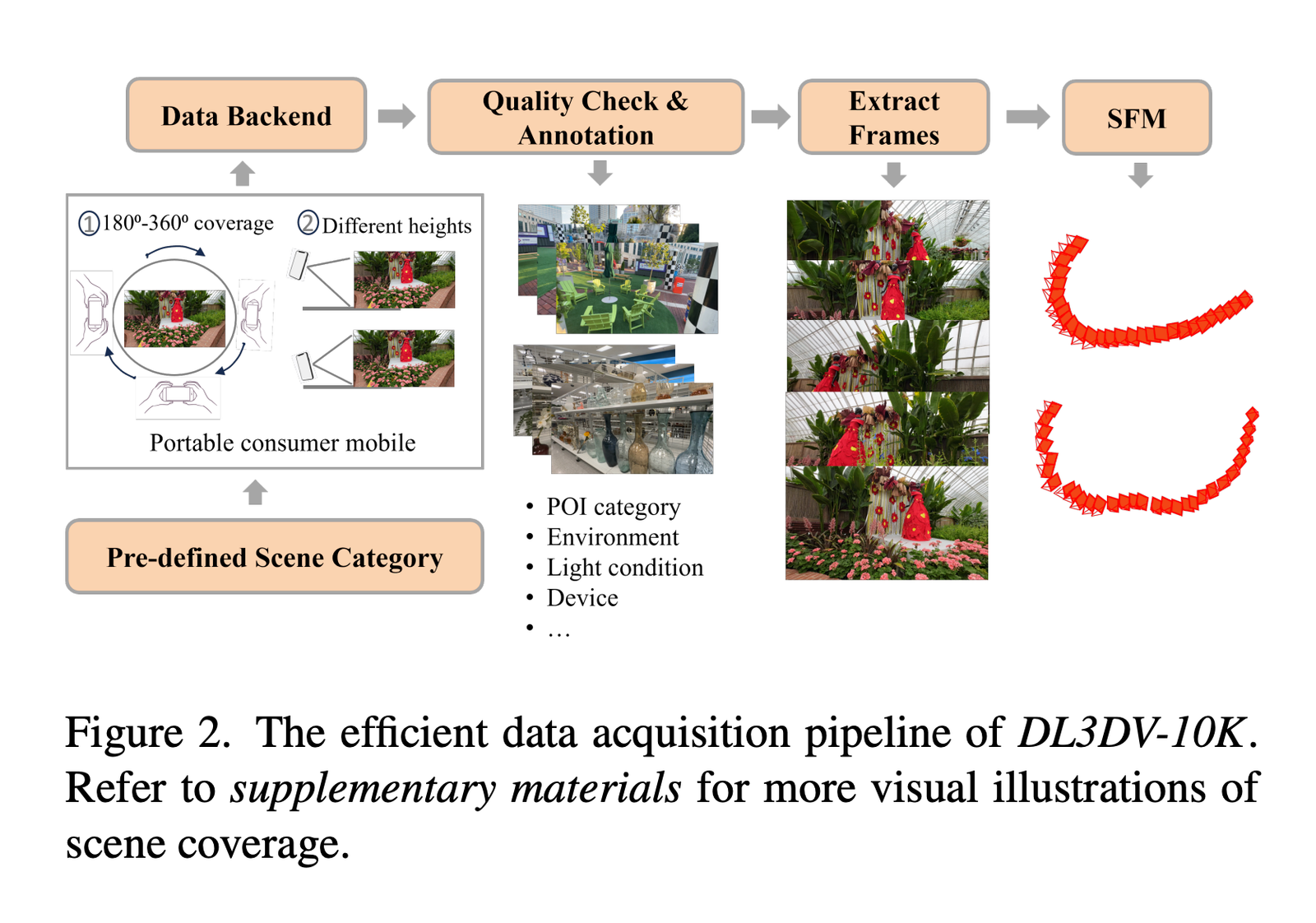
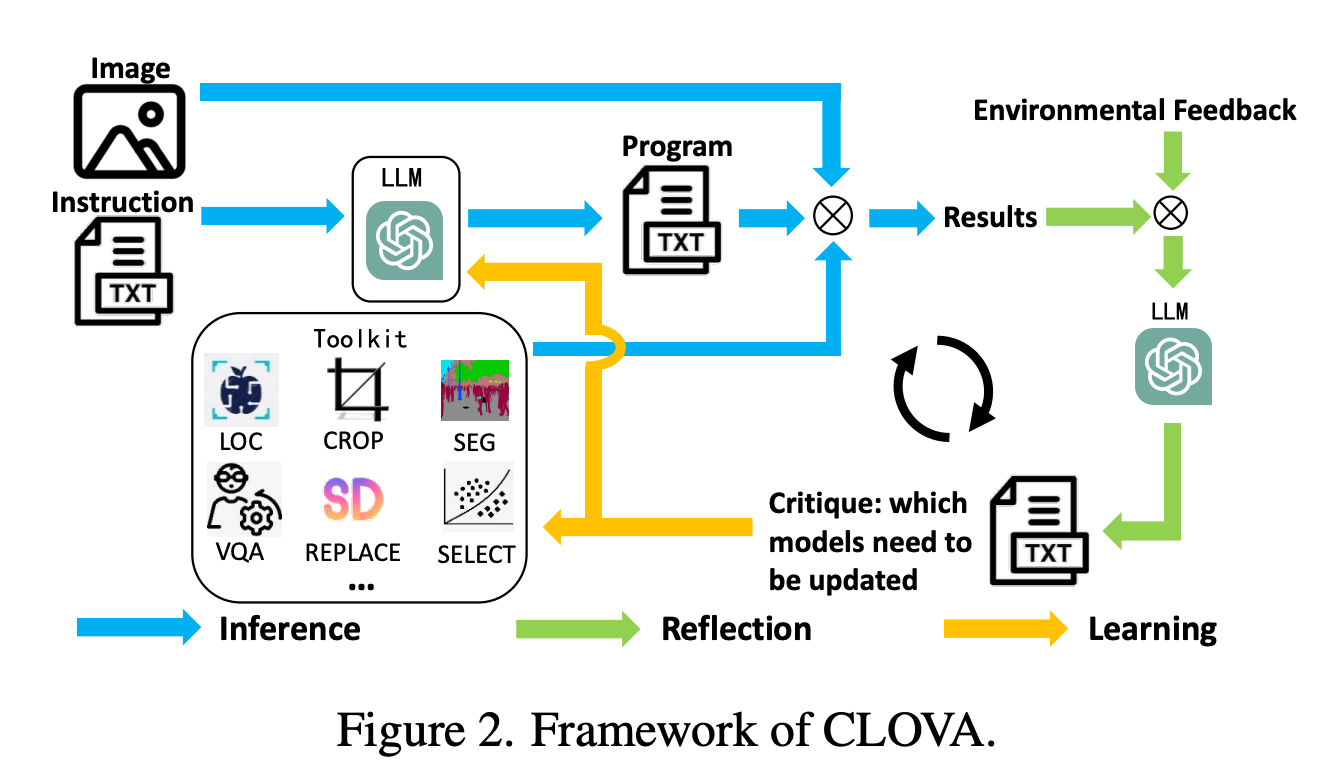
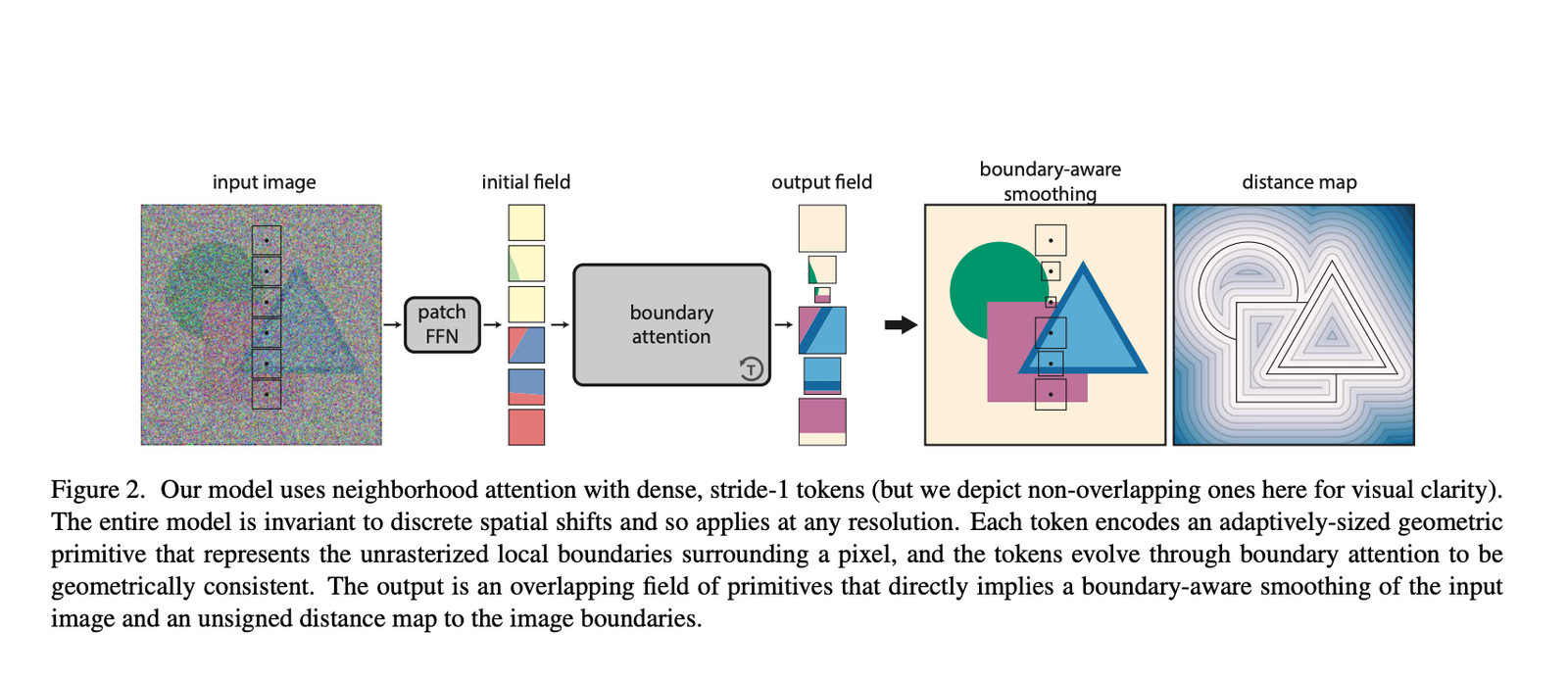
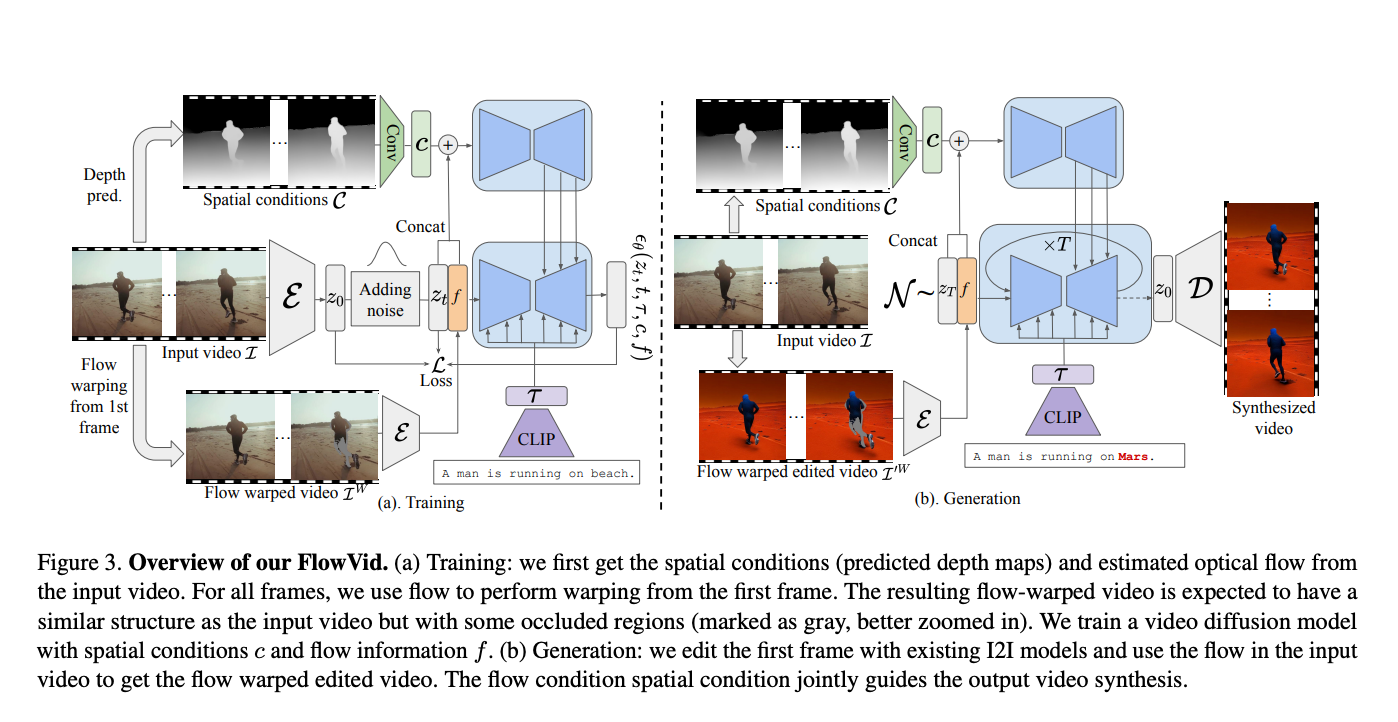
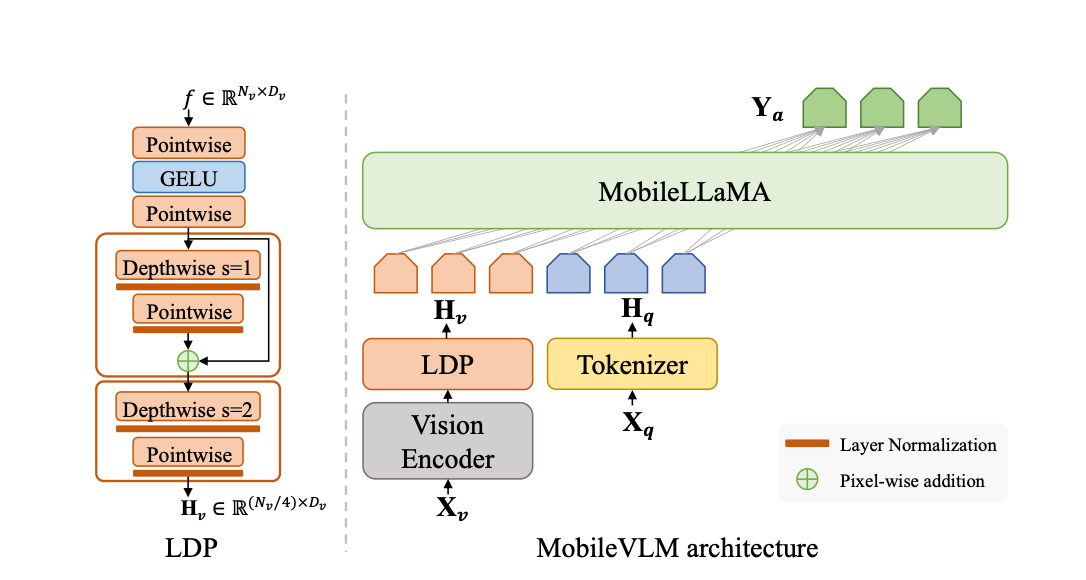
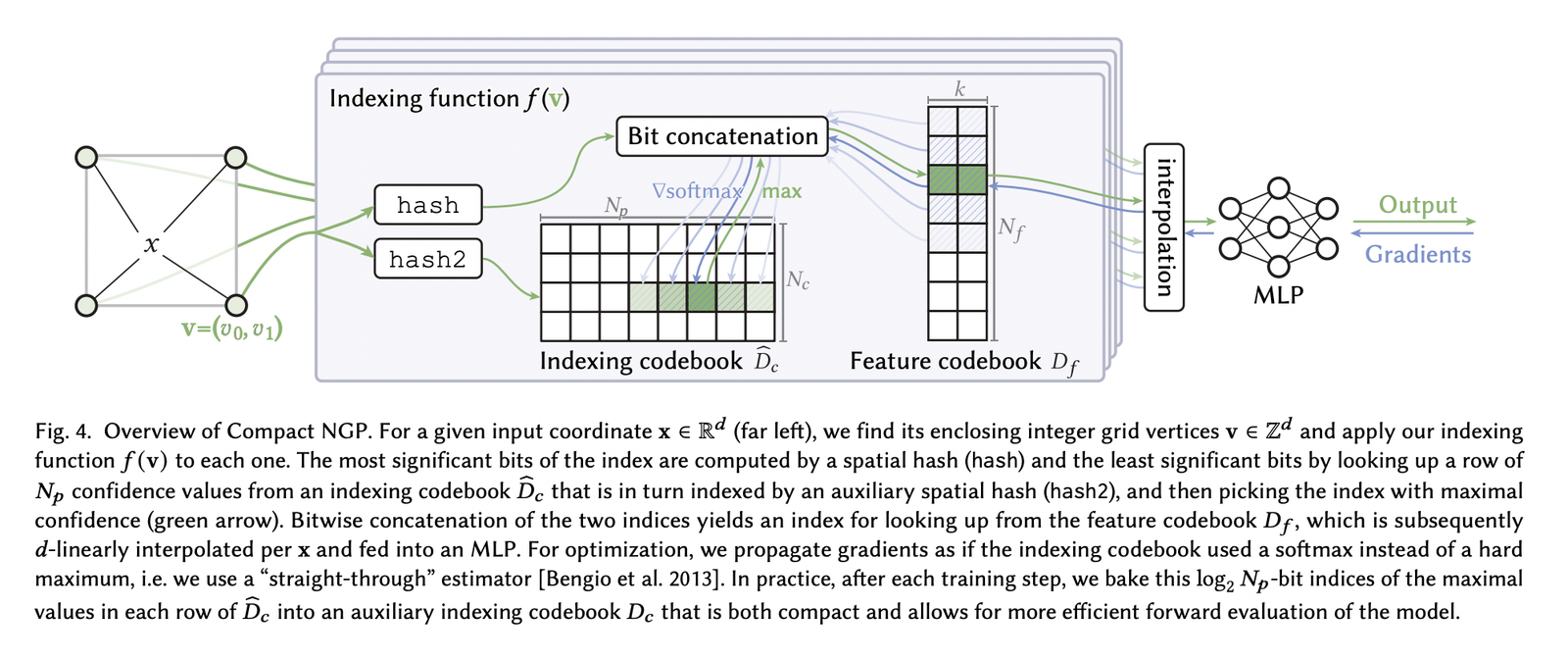
Artificial intelligence has always faced the issue of producing high-quality videos that smoothly integrate multimodal inputs like text and graphics. Text-to-video generation techniques now in use frequently concentrate on single-modal conditioning, using either text or images alone. The accuracy and control researchers can exert over the created films are limited by this unimodal technique, making…