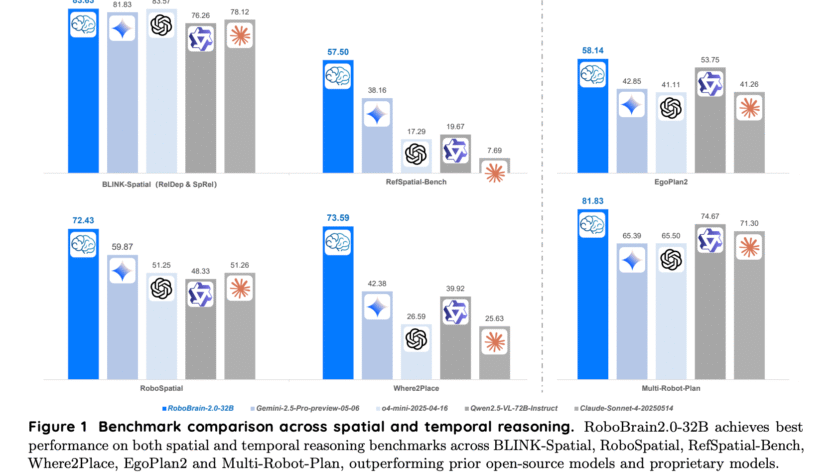
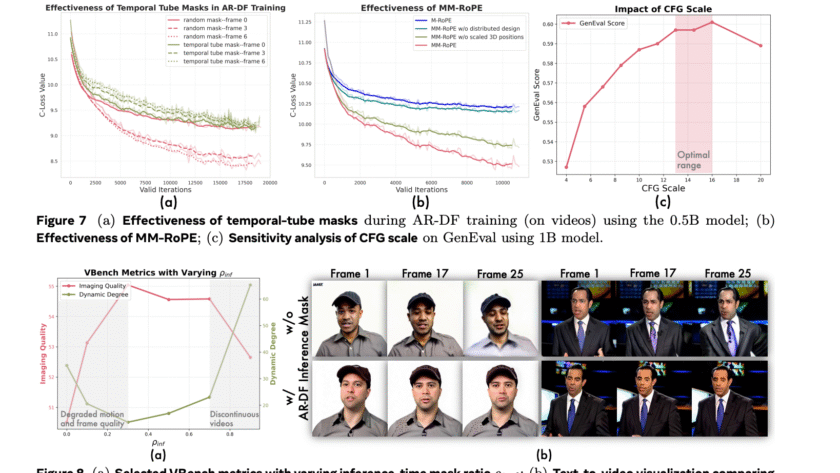
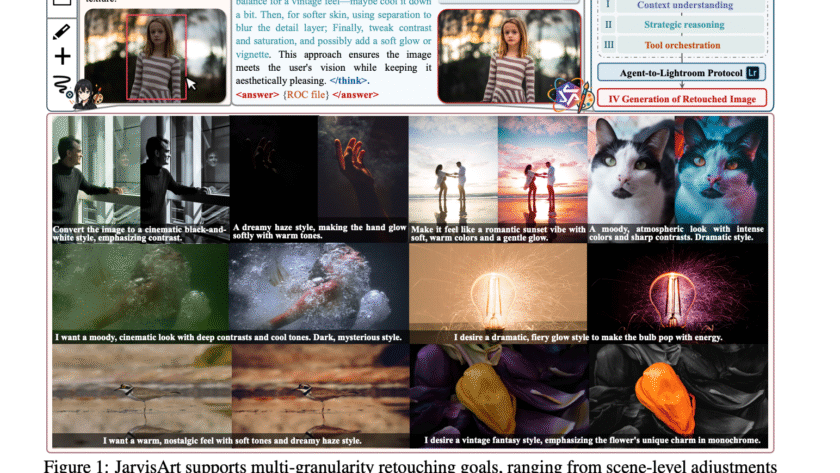
Advancements in artificial intelligence are rapidly closing the gap between digital reasoning and real-world interaction. At the forefront of this progress is embodied AI—the field focused on enabling robots to perceive, reason, and act effectively in physical environments. As industries look to automate complex spatial and temporal tasks—from household assistance to logistics—having AI systems that…