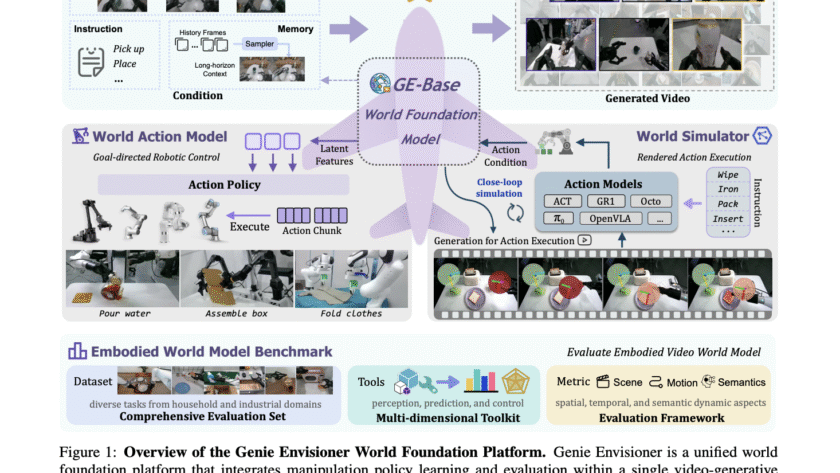
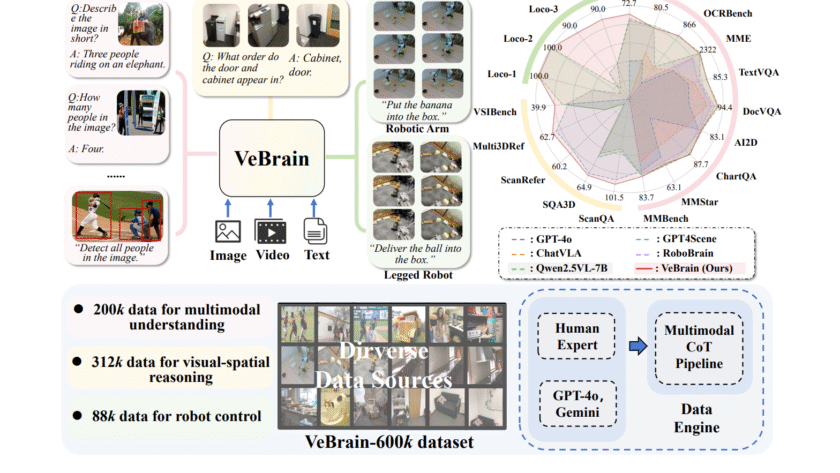
Embodied AI agents that can perceive, think, and act in the real world mark a key step toward the future of robotics. A central challenge is building scalable, reliable robotic manipulation, the skill of deliberately interacting with and controlling objects through selective contact. While progress spans analytic methods, model-based approaches, and large-scale data-driven learning, most…